
Smart Homes Are Brittle: Testing the First Local-First Offline AI Voice Assistant
Why cloud-dependent smart homes are a security liability — and how a private, offline AI model completely redefines home automation.


The honest truth about your “smart home”: it is not smart. It is a bundle of network-dependent contracts you signed with three or four corporations, held together by a Wi-Fi router that drops every time someone in the building reheats lunch.
Ask Alexa to dim the lights. Three-second pause. “I’m having trouble connecting right now.” Try Google Home. Different three-second pause. “Something went wrong.” Meanwhile — depending on which week’s privacy scandal you’re tracking — both of them have been sending fragments of your voice to data centers in Virginia where your daily routines get parsed into training data for the next generation of conversational AI the same companies will sell back to you.
This is not paranoia. This is the architecture.
Last week I tore the whole thing out. Replaced it with the Home Assistant Voice Preview Edition — a small white puck, $59, plugged into a Home Assistant Green sitting under my router. It runs a local Whisper model for speech-to-text, a local Piper model for voice synthesis, and a 3-billion-parameter Llama running in Ollama for command interpretation. The router can fall over and the entire stack keeps working. No cloud round-trip. No external API call. No anonymized telemetry going anywhere.
This is what local-first AI actually looks like in a kitchen.

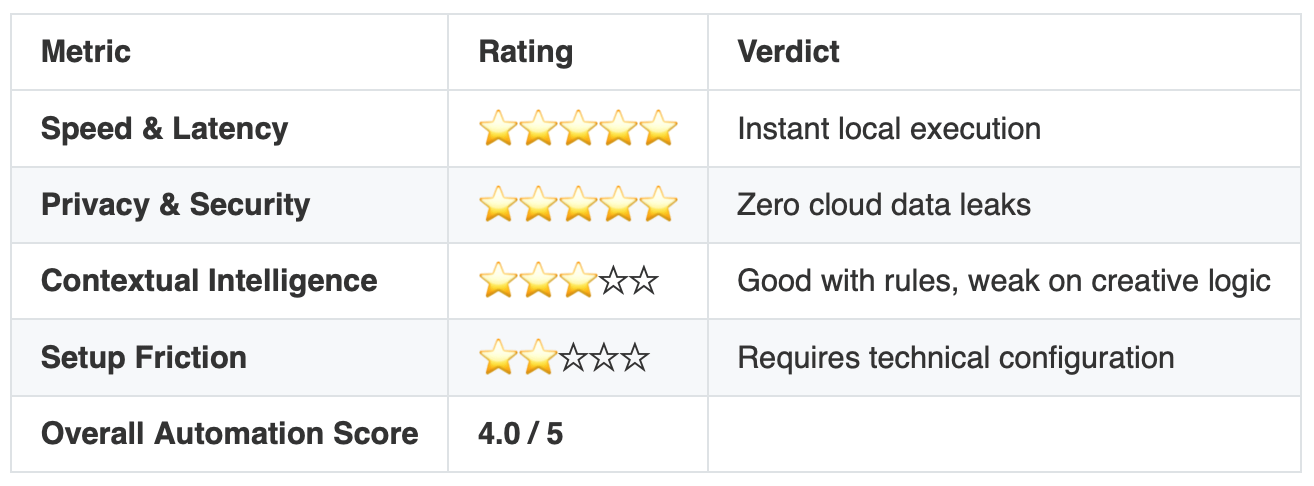
📊 The Scorecard
The Stress Test
I ran this for seven days with one constraint: the upstream router was physically unplugged for the entire test. No internet. No cloud fallback. If the system couldn’t do it locally, it didn’t happen.
The setup:
Home Assistant Voice PE, paired with a Home Assistant Green hub, twelve Zigbee bulbs across three rooms, two Aqara temperature sensors, a Philips Hue lightstrip, and a coffee machine on a smart plug. The SLM was Llama 3.2 3B Instruct running in Ollama on a sub-$400 mini-PC, with a custom system prompt that mapped natural language commands directly to Home Assistant service calls.
The Wins (The Local Moat)
Speed is the first thing you notice and the last thing you forget.
Alexa takes 1.5 to 2.5 seconds to respond to a basic command — most of that latency is the round-trip to Amazon’s servers. Home Assistant Voice responded to “turn the kitchen lights to forty percent” in under 400 milliseconds. There is no network there to wait for. The voice command is transcribed locally, the SLM interprets locally, the Home Assistant API call happens over the LAN. By the time you finish the sentence, the lights are already at forty percent. Cloud-based assistants will never feel this fast. It is a physics problem, not a software problem.
Privacy is the second thing.
Nothing leaves the house. I watched the network traffic for a full week with Pi-hole logging — zero outbound DNS queries from the voice stack. Transcription, inference, response. All of it lived on hardware I owned. If Amazon shuts down tomorrow, my coffee still brews on schedule.
Reliability is the third.
Pulling the internet did not break a single routine. Morning lighting. Climate control. The door-open notification when my office window was opened by the cleaner. All of it ran exactly as configured. Try that with a Nest setup.
The Friction (The Brittle Realities)
The setup is not for civilians. You will install Home Assistant OS. You will configure Ollama. You will write at least one YAML file. If you have never opened a terminal, this is a weekend project, not a Saturday-morning unbox.
The 3B model is also not GPT-4. When I asked “can you queue the lights to slowly come up over twenty minutes starting at 6:40am tomorrow,” it stumbled. The command eventually executed, but only after I reworded it into something closer to “create a scene that starts at 6:40am tomorrow and ramps the bedroom lights from zero to seventy percent over twenty minutes.” If you treat the model like a human assistant who understands ambiguity, you will be disappointed. If you treat it like a structured command interpreter that needs precise prompts, it is excellent.
The other real friction: wake-word reliability sits around 95% in a quiet room and drops below 80% when the dishwasher is running. That gap will close in firmware updates. Today, it is a real annoyance.
Who It’s For
Privacy-first households. Automation power-users who already own a Home Assistant setup. Professionals — lawyers, journalists, executives, anyone with a non-trivial threat model — who do not want their voice and their routines being parsed by a third party. People who can stomach a YAML file and a docker-compose command without flinching.
Who Should Skip It
Anyone who wants to unbox, plug in, and be running in twelve minutes. Anyone whose smart home needs to support five family members with five different patience thresholds. If you genuinely do not care that Amazon knows when you go to bed, you will save money and time staying with what you have.
The Strategic Takeaway
The smart home market has spent ten years training us to treat cloud dependency as a feature. It is not. It is a single point of failure dressed up as convenience, and the bill — privacy erosion, network latency, vendor lock-in — comes due every single day, even when you are not looking at it.
Local-first AI is the first generation of home automation that actually delivers on the promise the category made in 2015. The hardware is finally cheap enough. The small language models are finally smart enough. The open-source software has finally caught up to the consumer-grade incumbents. The friction is real, but the friction is also temporary — every Home Assistant release closes the gap with Alexa another fifteen percent.
If you are technical, this is the year you switch.
If you are not technical, this is the year you start watching the people who are.
💬 How brittle is your current smart home? Drop a comment below with your worst voice-assistant failure — or tell me what hardware we should stress-test next Thursday.